

Definisi
Data panel (panel data) adalah jenis data yang menggabungkan elemen data cross-section dan data time series. Dengan kata lain, data panel merupakan kumpulan data yang mencakup beberapa unit observasi (misalnya individu, perusahaan, negara) yang diamati dalam beberapa periode waktu.
Ciri-ciri Data Panel:
- Memiliki Dimensi Ganda:
- Dimensi cross-section → Observasi dari beberapa unit (misalnya perusahaan, negara).
- Dimensi time series → Observasi di berbagai periode waktu (misalnya tahun, bulan).
- Mengandung Informasi yang Lebih Kaya:
- Dibandingkan dengan data cross-section atau time series saja, data panel memberikan lebih banyak variasi, mengurangi multikolinearitas, dan meningkatkan efisiensi estimasi.
Jenis Data Panel:
- Balanced Panel: Jika semua unit memiliki jumlah observasi yang sama di setiap periode.
- Unbalanced Panel: Jika ada unit yang tidak memiliki data pada beberapa periode.
Analisis Data Panel:
- Dalam analisis regresi data panel, ada tiga pendekatan utama:
- Common Effect Model (CEM) → Tidak mempertimbangkan perbedaan antar unit atau waktu.
- Fixed Effect Model (FEM) → Mempertimbangkan perbedaan spesifik antar unit (dengan efek tetap).
- Random Effect Model (REM) → Mengasumsikan perbedaan antar unit bersifat acak.
Perbedaan data panel vs cross-section vs time series
|
karakteristik |
Data cross section | Data time series |
Data panel |
| Definisi | Data yang dikumpulkan dari beberapa unit pada satu titik waktu tertentu. | Data yang dikumpulkan dari satu unit dalam beberapa periode waktu. | Kombinasi dari data cross-section dan time series, yaitu beberapa unit yang diamati dalam beberapa periode waktu. |
| Dimensi | Hanya dimensi cross-section (banyak unit, satu waktu). | Hanya dimensi time series (satu unit, banyak waktu). | Memiliki dua dimensi: unit dan waktu. |
| Contoh unit observasi | Individu, perusahaan, negara, dll. | Harga saham, suhu harian, GDP suatu negara, dll. | Data perusahaan dari tahun ke tahun, data ekonomi negara dari waktu ke waktu. |
| Contoh data | Survei pendapatan rumah tangga di Indonesia pada tahun 2023. | Harga saham perusahaan X dari tahun 2010–2023. | Pendapatan 10 perusahaan dari tahun 2010–2023. |
| keunggulan | Lebih sederhana dan mudah dianalisis. | Cocok untuk melihat tren dan pola perubahan seiring waktu. | Lebih informatif karena mengandung aspek waktu dan unit observasi yang beragam. |
| kelemahan | Tidak bisa menangkap perubahan dalam waktu. | Tidak bisa membandingkan antar unit. | Lebih kompleks dalam analisis dan membutuhkan metode khusus seperti regresi data panel. |
Contoh aplikasi data panel dalam penelitian
Data panel banyak digunakan dalam penelitian ekonomi, bisnis, keuangan, dan sosial. Berikut adalah beberapa contoh aplikasi data panel dalam penelitian:
- Ekonomi Makro & Keuangan
Judul: Pengaruh Investasi Asing Langsung (FDI) dan Pertumbuhan Ekonomi terhadap Pengangguran di Negara ASEAN (2010–2023)
- Variabel terikat: Tingkat pengangguran (%)
- Variabel bebas: FDI (% dari PDB), Pertumbuhan PDB (%)
- Data panel: 10 negara ASEAN diamati dari tahun 2010 hingga 2023
Manfaat:
- Mengetahui apakah investasi asing benar-benar berkontribusi dalam mengurangi pengangguran.
- Bisa membandingkan pengaruh antar negara dan melihat trennya dalam jangka waktu tertentu.
- Perbankan & Keuangan Perusahaan
Judul: Faktor yang Mempengaruhi Profitabilitas Bank di Indonesia (2015–2023)
- Variabel terikat: ROA (Return on Assets)
- Variabel bebas: CAR (Capital Adequacy Ratio), NPL (Non-Performing Loan), BOPO (Beban Operasional terhadap Pendapatan Operasional)
- Data panel: 20 bank di Indonesia diamati dari tahun 2015 hingga 2023
Manfaat:
- Bisa membandingkan profitabilitas antar bank dan melihat faktor dominan yang mempengaruhi ROA.
- Dapat menangkap perubahan regulasi perbankan dari waktu ke waktu.
- Pasar Saham
Judul: Dampak Likuiditas Saham dan Volatilitas Pasar terhadap Return Saham di BEI (2018–2023)
- Variabel terikat: Return saham
- Variabel bebas: Likuiditas saham, Volatilitas pasar
- Data panel: 50 perusahaan yang terdaftar di Bursa Efek Indonesia (BEI) dari tahun 2018 hingga 2023
Manfaat:
- Bisa mengetahui apakah saham yang lebih likuid cenderung memberikan return lebih tinggi.
- Memungkinkan analisis perbedaan antara perusahaan besar dan kecil.
- Sektor Industri & Perusahaan
Judul: Efek Digitalisasi terhadap Kinerja UMKM di Indonesia (2016–2023)
- Variabel terikat: Pendapatan UMKM
- Variabel bebas: Penggunaan media sosial, Jumlah transaksi online, Investasi teknologi
- Data panel: 500 UMKM diamati selama 8 tahun
Manfaat:
- Bisa mengukur dampak digitalisasi terhadap pertumbuhan UMKM secara lebih akurat.
- Dapat membandingkan kinerja UMKM yang sudah go digital vs yang belum.
- Kesehatan & Sosial
Judul: Pengaruh Pola Makan dan Aktivitas Fisik terhadap Obesitas pada Remaja di 10 Kota Besar (2012–2022)
- Variabel terikat: Tingkat obesitas
- Variabel bebas: Konsumsi makanan cepat saji, Frekuensi olahraga
- Data panel: Remaja di 10 kota besar dari tahun 2012 hingga 2022
Manfaat:
- Bisa melihat apakah ada tren peningkatan obesitas seiring dengan perubahan pola makan dan aktivitas fisik.
- Dapat membandingkan pola di berbagai kota dengan karakteristik yang berbeda.
- Pendidikan
Judul: Dampak Penggunaan Teknologi dalam Pembelajaran terhadap Prestasi Akademik Siswa (2015–2023)
- Variabel terikat: Nilai rata-rata ujian siswa
- Variabel bebas: Akses ke e-learning, Penggunaan internet untuk belajar
- Data panel: 100 sekolah di Indonesia dari tahun 2015 hingga 2023
Manfaat:
- Bisa mengukur apakah penggunaan teknologi benar-benar berdampak positif terhadap prestasi siswa.
- Membandingkan antara sekolah di perkotaan dan pedesaan.
Langkah langkah analisis di Eviews
masuk ke eviews lalu klik New -> Workfile.

Pada workfile structure type pilih “Balanced Panel”, lalu pada kolom frequency bisa diisi Annual (jika data yang tersedia memiliki runtun waktu dalam periode tahunan). Untuk start date & end date merupakan periode pada masing masing cross section, Number of cross sectional merupakan jumlah cross section dalam dataset

Copy data dari excel, lalu input ke eviews dengan klik Quick -> Empty Group

Jika sudah di paste, kurang lebih tampilan dataset akan seperti ini.

Selanjutnya akan dilakukan uji pemilihan model yang pertama yaitu uji chow dengan cara menyeleksi variabel yang sebelumnya di input lalu klik -> open -> as.Equation

Masukan variabel yang tadi telah diseleksi dengan cara di ketik secara manual seperti gambar dibawah

klik panel options lalu pilih Fixed pada Cross section dan klik ok.

Klik View pada output yang baru saja muncul kemudian klik Fixed/Random Effect Testing -> Redundant Fixed Effect – Likelihood Ratio.

Output yang dihasilkan akan seperti ini.

Dari uji Chow kita mendapatkan nilai prob < 0.05 maka model yang terpilih pada uji chow adalah model FEM.
Karena yang terpilih adalah model FEM, maka perlu dilakukan uji hausman dengan cara klik estimate pada output sebelumnya kemudian klik panel option lalu piih random pada cross section dan klik OK.

Setelah muncul output, klik view pada output kemudian klik Fixed/Random Effects Testing -> Correlated Random Effects – Hausman Test

Didapatkan output seperti berikut dengan interpretasi : karena prob > 0.05, maka model yang terpilih adalah model REM

Selanjutnya lakukan uji LM untuk menentukan apakah model terbaiknya adalah REM atau CEM. Dengan cara : klik estimate pada output sebelumnya, kemudian klik none pada cross section dan klik ok.

Setelah keluar output, klik view -> Fixed/Random Effects Testing -> Ormitted Random Effects – Lagrange Multiplier.

Didapatkan output uji Lm sebagai berikut dengan interpretasi : prob < 0.05 (Breusch – Pagan x Coss Section), maka model yang terpilih adalah model REM.

Setelah menentukan model terbaiknya adalah model REM, selanjutnya adalah uji asumsi klasik Multikolinearitas & Heteroskedastisitas
Untuk uji multikolinearitas, klik Quick -> Group statistics -> Correlations.
Input semua variabel dependen (di kasus ini x1, x2, x3, x4, x5) dan klik ok.

Didapatkan hasil sebagai berikut. Dikatakan terbebas dari multikolinearitas apabila semua nilai korelasi antar variabel bebas < 0.85. interpretasi : semua korelasi bernilai < 0.85 kecuali korelasi antara x2 & x3 (0.990804 > 0.85) ini mengindikasikan adanya multikolinearitas dan harus ditangani

Karena pada x2 & x3 terdapat korelasi yang > 0.85, maka disini akan dilakukan salah satu penanganan yaitu Principal Component Analysis dengan langkah langkah sebagai berikut :
Pilih variabel bebas yang memiliki korelasi lebih dari 0.85 kemudian klik kanan -> open -> as.Group

Klik view pada tabel yg berisi x2 & x3 lalu klik principal components

Pada kondisi ini langsung klik ok.

Didapat hasil seperti berikut, dalam memilih variabel PC yang nantinya akan menggantikan variabel yang bermasalah (dalam hal ini x2 & x3) harus dipilih PC dengan cumulative variance yang besarnya >= 70% (dalam hal ini PC1) dengan cumulative variance sebesar 99.54%.

Buat variabel baru (PC1) dengan formula (PC1 = 0.707107 * X2 + 0.707107 * X3)

Klik Quick -> Group statistics -> Correlations

Input variabel bebas seperti berikut lalu klik ok.

Didapatkan hasil seperti berikut dengan kondisi tidak lagi terdapat multikolinearitas karena semua nilai korelasi antar variabel bebas < 0.85.

Selanjutnya untuk uji heteroskedastisitas bisa digunakan grafik residual dengan langkah – langkah berikut :
Pilih variabel yang akan di regresikan pada dengan model REM (sesuaikan dengan model terbaik yang telah terpilih) lalu klik kanan -> open -> as.Equation

Masukan variabel yang akan di regresikan

Pada panel options pilih Random dan klik ok.

Setelah muncul output, klik view pada output lalu klik Actual – Fitted – Residual -> Residual Graph.
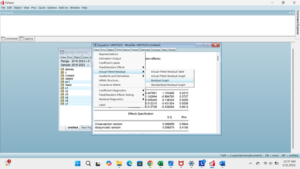
Pada residual graph terlihat tidak ada yang melewati batas atas (500) dan batas bawah (-500) yang berarti varians residual konstan. Oleh karena itu tidak terjadi heteroskedastisitas.

Uji Signifikansi Parameter bisa dilakukan dengan pilih variabel apa saja yang ingin di regresikan dengan model REM (model yang sebelumnya terpilih di uji pemilihan model) lalu klik kanan -> open -> as.Equation

Masukan variabel yang akan di regresikan kemudian klik panel options.

Pada panel options, pilih Random di bagian cross section dan klik ok.


